1. Introduction
This is the second of a series of blog posts about collecting and analysing WWW hyperlink networks and text data. The first post focused on how to collect hyperlink data using the web crawler in vosonSML, and how to process the hyperlink data so as to produce hyperlink networks that can be used for research. The present post is focused on how to collect and process website text content, and we also provide some basic frequency analysis of words/terms extracted from the web pages.
2. Identifying the web pages from which to collect text content
The vosonSML web crawler uses the rvest R package to crawl web pages but only the hyperlinks are extracted from these web pages: website text content is not retained.
So our plan is to use rvest directly (not via vosonSML) to crawl the relevant web pages and this time, we will extract and work with the text content (not the hyperlinks).
To find what pages we need to crawl, our starting point is the “seeds plus important websites” network that we created in the previous post. We saved this to a graphml file.
library(igraph)
library(dplyr)
library(knitr)
library(rvest)
g <- read.graph("g_seedsImp2.graphml", format="graphml")
gIGRAPH 417d86a DNW- 31 31 --
+ attr: type (g/c), name (v/c), seed (v/l), keep (v/n), id
| (v/c), weight (e/n)
+ edges from 417d86a (vertex names):
[1] cipesa.org ->un.org
[2] cipesa.org ->itu.int
[3] datainnovation.org ->itif.org
[4] datasovereigntynow.org->internationaldataspaces.org
[5] globaldatajustice.org ->itu.int
[6] id4africa.com ->un.org
[7] id4africa.com ->id-day.org
+ ... omitted several edgesWe want to collect text content for the 31 sites in this network. But it is important to remember that we are only interested in website text content that relates to our research topic (data sovereignty) and so we want to target the web pages on these sites that are are most likely to be related to our research topic.
So what we will do is use the raw web crawl data returned by vosonSML (see the previous post) to identify exactly what pages we need to collect website text content from.
#read in the raw crawl data returned by vosonSML
crawlDF <- readRDS("crawlDF_20_sites_depth1.rds")
#find the pages that correspond to the sites in the "seeds plus important" network
textPages <- NULL
for (i in 1:vcount(g)){
#cat("site:", V(g)$name[i], ", seed:",V(g)$seed[i],"\n")
ind <- grep(paste0(V(g)$name[i],"$"), crawlDF$parse$domain)
#cat("\tnumber of pages:", length(ind), "\n")
textPages <- rbind(textPages, data.frame(domain=V(g)$name[i],
page=crawlDF$url[ind], seed=V(g)$seed[i]))
}
#it is possible that pages are not-unique (e.g. two seed pages can link to the same third page)
#remove duplicate pages
textPages <- textPages %>% distinct(page, .keep_all = TRUE)
head(textPages) domain page seed
1 ada-x.org https://www.ada-x.org/a-propos/partenaires TRUE
2 ada-x.org https://www.ada-x.org/en TRUE
3 ada-x.org https://www.ada-x.org/en/about/mandate-history TRUE
4 ada-x.org https://www.ada-x.org/en/about/partners TRUE
5 ada-x.org https://www.ada-x.org/en/about/team TRUE
6 ada-x.org https://www.ada-x.org/en/about/volunteer-internship TRUEnrow(textPages) [1] 1085The above shows that if were were to collect text from all pages for the 31 websites in the “seeds plus important” network that have been identified (via the vosonSML web crawl), then we would need to collect 1085 web pages.
The following shows the number of pages identified for each of the seed sites.
#number of pages identified for seed sites
kable(textPages %>% filter(seed==TRUE) %>% group_by(domain) %>% summarise(n = n()))| domain | n |
|---|---|
| ada-x.org | 34 |
| botpopuli.net | 35 |
| cipesa.org | 86 |
| cis-india.org | 35 |
| cksindia.org | 69 |
| cryptoaltruism.org | 35 |
| datainnovation.org | 70 |
| datasovereigntynow.org | 13 |
| digitalasiahub.org | 89 |
| edri.org | 35 |
| globaldatajustice.org | 25 |
| id4africa.com | 41 |
| id4africakhub.org | 38 |
| indigenousdatalab.org | 24 |
| internationaldataspaces.org | 85 |
| itif.org | 81 |
| iwgia.org | 63 |
| mydata.org | 42 |
| orfonline.org | 143 |
| womeninlocalization.org | 1 |
The following shows the number of pages identified for each of the non-seed important sites.
#number of pages identified for non-seed important sites
kable(textPages %>% filter(seed==FALSE) %>% group_by(domain) %>% summarise(n = n()))| domain | n |
|---|---|
| doi.org | 12 |
| gida-global.org | 2 |
| id-day.org | 2 |
| id4africa-ambassadors.org | 2 |
| itu.int | 2 |
| lawfareblog.com | 4 |
| maiamnayriwingara.org | 3 |
| un.org | 3 |
| whitehouse.gov | 2 |
| worldbank.org | 2 |
| wto.org | 7 |
It is apparent that there are many more web pages identified for seed sites, compared with non-seed sites. This makes sense, because only the seed sites have been crawled by vosonSML: so the crawler has identified these web pages by crawling the seed pages. In contrast, only a handful of pages have been identified for each non-seed important websites: these are pages that were linked to by the seed sites.
It should be noted out that only one unique page has been identified for the seed site womeninlocalization.org. However this is due to the fact that in the previous post we used pagegrouping to merge womeninlocalization.org and womeninlocalization.com together into a site labelled womeninlocalization.org. The following shows that the crawler in fact found over 60 pages for womeninlocalization.com.
[1] 2crawlDF$url[ind][1] "https://womeninlocalization.org/membership-login"
[2] "https://womeninlocalization.org/membership-login"[1] 67head(crawlDF$url[ind])[1] "https://womeninlocalization.com"
[2] "https://womeninlocalization.com/about"
[3] "https://womeninlocalization.com/about/advisory-board"
[4] "https://womeninlocalization.com/about/board-members"
[5] "https://womeninlocalization.com/about/program-directors"
[6] "https://womeninlocalization.com/become-a-sponsor" For the purposes of this exercise we do not want to be collecting text content from 1085 web pages: this would be a significant undertaking to collect and process these data. Another issue is that many of the web pages identified for the seed sites will not contain content relevant to our research topic of data sovereignty. This is because the web crawler is quite a blunt object: it is simply finding hyperlinks to pages within the seed site, and not taking account of whether these pages are relevant or not to our research topic.
So our strategy (in order to keep the exercise simple and also maximise the likelihood of collecting relevant text data) is as follows:
- For the seed sites, we will collect text content only from the web pages we originally identified for the crawling
- For the non-seed important sites, we will collect text content from the web pages identified by the crawler. By construction, these are pages that are linked to by two or or more seed sites (this is how we constructed the “seeds plus important” network in the previous post), and so we can expect that the text content on these pages is relevant to our study.
| page | type | max_depth | domain | country |
|---|---|---|---|---|
| https://womeninlocalization.com/partners/ | int | 1 | womeninlocalization.com | US |
| https://womeninlocalization.com/data-localization-laws-around-the-world/ | int | 1 | womeninlocalization.com | US |
| https://iwgia.org/en/network.html | int | 1 | iwgia.org | Denmark |
| https://www.iwgia.org/en/indigenous-data-sovereignty/4699-iw-2022-indigenous-data-sovereignty.html?filter_tag[0]=37 | int | 1 | iwgia.org | Denmark |
| https://indigenousdatalab.org/networks/ | int | 1 | indigenousdatalab.org | US |
| https://indigenousdatalab.org/projects-working/ | int | 1 | indigenousdatalab.org | US |
#just keep the columns we will work with
#note that why "domain" is specified in this csv file, we will extract this
#programmatically from the URL
pagesForText <- pages %>% select(page)
#function from https://stackoverflow.com/questions/19020749/function-to-extract-domain-name-from-url-in-r
domain <- function(x) strsplit(gsub("http://|https://|www\\.", "", x), "/")[[c(1, 1)]]
#following could be done more elegantly, but it works...
dd <- sapply(pagesForText$page, domain)
pagesForText$domain <- as.character(dd)
#modify domain to account for fact we use (in seeds+important network)
#womeninlocalization.org not womeninlocalization.com
pagesForText$domain[which(pagesForText$domain=="womeninlocalization.com")] <- "womeninlocalization.org"
#not sure if we need this
pagesForText$seed <- TRUE
#check that we've got all the seed pages
#just a sanity check...
seedDom <- V(g)$name[V(g)$seed==TRUE]
#all OK
length(which(is.na(match(seedDom, unique(pagesForText$domain)))))[1] 0So we have the web pages (for text collection) for the seed sites. Now we will add in the web pages for non-seed important sites.
#dataframe with pages for non-seed sites
dd <- textPages %>% filter(seed==FALSE) %>% relocate(page, domain, seed)
#append to dataframe for seed sites
pagesForText <- rbind(pagesForText, dd)
nrow(pagesForText)[1] 79So we have 79 pages which we will use rvest to collect text content from. The following shows that there are some duplicated web pages for non-seed sites - the “http” and “https” version of the same page. We may adjust for this later on.
| page | domain | seed |
|---|---|---|
| http://www.gida-global.org | gida-global.org | FALSE |
| https://www.gida-global.org | gida-global.org | FALSE |
| http://www.worldbank.org | worldbank.org | FALSE |
| https://www.worldbank.org | worldbank.org | FALSE |
3. Collecting the website text content
Here we make use of the rvest R package (“Easily Harvest (Scrape) Web Pages”), which provides “wrappers around the ‘xml2’ and ‘httr’ packages to make it easy to download, then manipulate, HTML and XML.”
3.1 Example web page
Using rvest can be quite a complicated, requiring an understanding of how web pages are structured. Here we use rvest in a very simple way: we only use it to extract website text that is contained in HTML paragraph tags.
Before using rvest to collect text content for all our web pages, it is useful to first look at its use for an example web page: Bot Populi which is an “alternative media platform dedicated to looking at all things digital from a social justice and Global South perspective.”

If we look at the source code for this web page, we see the use of the HTML paragraph tags.

Now we will use rvest to download the web page and extract text content from the HTML paragraph tags.
testurl <- pagesForText$page[7]
testurl
#fetch the webpage
testpage <- read_html(testurl)
#As explained in following post:
#https://stackoverflow.com/questions/57764585/how-to-save-and-read-output-of-read-html-as-an-rds-file
#we need to use as.character() on the object returned by read_html()
#if we want to save it to RDS file
#we save the object returned by read_html() to file because below we are
#just extracting text from paragraph html tags, but in future might want to
#extract other tags
saveRDS(as.character(testpage), "testpage.rds")testpage <- readRDS("testpage.rds")
#note that use of read_html() in following is because we above used
#as.character() to save the object to RDS file
testpage <- read_html(testpage)
#extract the paragraphs
p_text <- html_nodes(testpage, 'p') %>% html_text()
head(p_text, n=3)[1] "Bot Populi is an alternative media platform dedicated to looking at all things digital from a social justice and Global South perspective. It was founded in 2018 by seven global, digital justice organizations."
[2] "Digital technologies have been the transformative force of the 21st century, changing the way we live, work, and interact. Those who control data mark and mediate our social location in society. They also decide who is included and excluded from the digital ecosystem. Data, and the digital intelligence harvested from it, are today the purveyors of destiny. As data-based systems become the basis of development, important questions about justice and rights emerge.\nWe explore these questions about the ways in which the digital world affects different aspects of our lives — in obvious and unexpected ways — through articles, podcasts, and videos. Our contributors include passionate and committed scholars, activists and visionaries from around the world working on issues of digital justice."
[3] "We aim to meaningfully shape the public discourse on digitalization. In the process, we seek to influence the norms, rules, and practices that contribute to transformative change." In this exercise we will just work with the paragraph text, but it should be noted that useful text content might be stored in other HTML tags such as titles (header tags “h1”, “h2” etc.) and anchor tags.
3.2 Collecting paragraph text from all the web pages
In the code below we use the rvest read_html() function to collect the web pages for all our seed and non-seed sites, and we store the objects returned by read_html() in a list, and save this list object to an rds file for later use.
Before we collect the html data, we are going to remove some web pages that caused problems (rvest failed while collecting the html). For this exercise, we don’t try to figure out why these URLs are causing problems for rvest and we do not try to improve the code to make it more robust (e.g. via error handling).
We also note that some of the URLs are for pdf files - these would normally be removed.
#first remove problematic URLs
url_problem <- c(
"https://docs.wto.org/dol2fe/Pages/SS/directdoc.aspx?filename=q:/WT/GC/W798.pdf&Open=True xxiv",
"https://doi.org/10.1002/ajs4.141", #Error in open.connection(x, "rb") : HTTP error 503.
"https://www.id4africa-ambassadors.org", #Error in open.connection(x, "rb") : HTTP error 404.
"https://www.id4africa-ambassadors.org/iic" #Error in open.connection(x, "rb") : HTTP error 404.
)
pagesForText <- pagesForText %>% filter(!page %in% url_problem)
#now collect the html and store in list
L_html <- list()
for (i in 1:nrow(pagesForText)){
url_i <- pagesForText$page[i]
cat("working on:", url_i, "\n")
L_html[[url_i]] <- read_html(url_i)
#if (i > 5)
# break
}
#See note above about needing to use as.character() on
#the object returned by read_html()
for (i in names(L_html)){
L_html[[i]] <- as.character(L_html[[i]])
}
saveRDS(L_html, "L_html.rds")Now we iterate over the webpages in the list, extracting and joining the paragraphs and putting them in the textContent dataframe that we will later use for text analysis.
L_html <- readRDS("L_html.rds")
#this is not an efficient way of creating a dataframe, but will do here...
textContent <- NULL
for (i in names(L_html)){
#cat("working on:", i, "\n")
#note that use of read_html() in following is because we above used
#as.character() to save the object returned by read_html() to RDS file
p_text <- html_nodes(read_html(L_html[[i]]), 'p') %>% html_text()
#print(head(p_text))
textContent <- rbind(textContent,
data.frame(page=i, text=paste0(p_text, collapse=" ")))
}
#save the text content data frame for later use (in another blog post)
saveRDS(textContent, "textContent.rds")4. Word frequency analysis
The final part of this blog post involves a basic analysis of the website text content: computing word frequencies. We will use the tidytext package. In the following, we will only work with unigrams (we’ll look at bigrams in a later post).
Word frequency barplot
First, we will present the word frequencies in a barplot.
library(tidytext)
#creating copy of the dataframe containing text, so can reuse code
df <- textContent
#dplyr syntax
df <- df %>% unnest_tokens(word, text)
nrow(df)[1] 138293#df %>% count(word)
#remove stopwords (not really necessary for this dataset)
#df %>%
# anti_join(get_stopwords())
#Word frequency bar chart
library(ggplot2)
library(crop)
png("word_frequency_barplot.png", width=800, height=800)
df %>%
anti_join(stop_words) %>%
count(word, sort=TRUE) %>%
top_n(10) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip() +
theme_grey(base_size = 22)
dev.off.crop("word_frequency_barplot.png")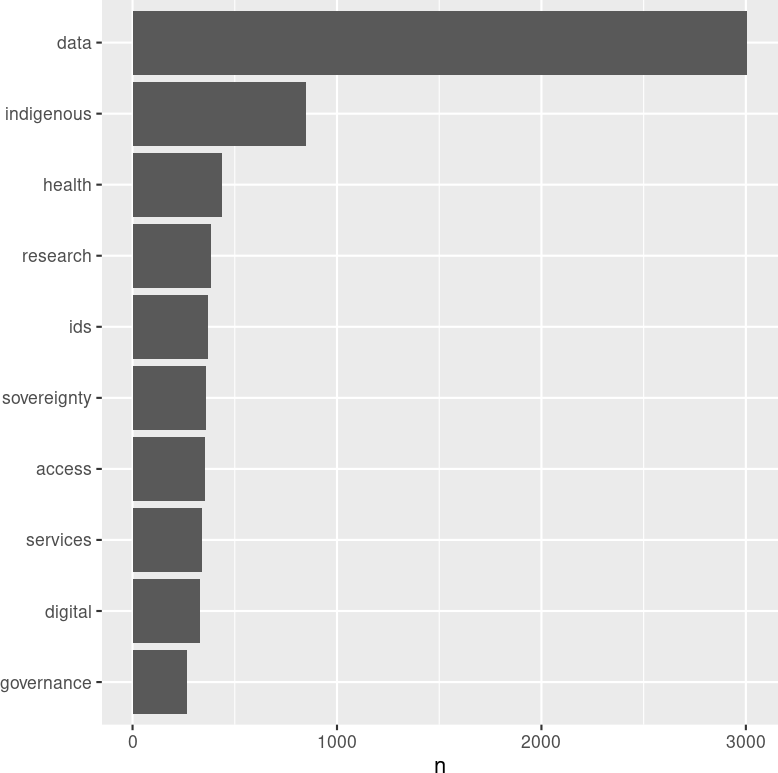
Wordcloud
Next, we will present the word frequencies in a wordcloud.

The wordcloud is simply another way of visualising the word frequency counts: in the above wordcloud, the words that are used more often are larger and towards the centre of the figure. The wordcloud shows what we saw in the frequency barplot above: the term ‘data’ was the most frequently use term. This shouldn’t come as a surprise since by construction, issues that are being focused on by the websites in our data set are related to data, more specifically ‘data sovereignty’.
While the wordcloud looks OK, there are a couple of simple things we can do to improve it. First, there are some numbers in the wordlcoud, so we will remove numbers from the terms extracted from the web pages. Second, the dominant word is ‘data’ but this is not really that informative since all the websites are by construction going to have something to do with data, so we will add the word ‘data’ to a custom stopword list.
#remove tokens that are numbers
df <- df %>% filter(!grepl("[[:digit:]]", word))
#create a custom stopword dataframe
stop_words2 <- rbind(stop_words, data.frame(word="data", lexicon="custom"))
png("wordcloud2.png", width=800, height=800)
df %>%
anti_join(stop_words2) %>%
count(word) %>%
with(wordcloud(word, n, max.words = 200, random.order = FALSE, scale=c(5, 1)))
dev.off.crop("wordcloud2.png")
The improved wordcloud (with ‘data’ removed) now more clearly reveals other key terms such as ‘indigenous’, ‘research’, and ‘health’. These words can be seen as a representation of texts indicating that a variety of issues such as indigenousity, research and health are being discussed by organisations addressing the ‘data sovereignty’ topic. Different organisations might be concerned with different issues while using the same term. For example, some organisations mention the term ‘data sovereignty’ when discussing about indigenous-related issues. Some others direct their discussion to address ‘research’ or ‘health’ related issues. This wordcloud provides a visual representation of texts which is very useful as a first step in our text analysis.
Comparison cloud
Finally, we will present a comparison cloud showing the words used by (or most associated with) the Global North versus the those used by the Global South. To do this, we first need to manually create a Global North/South classification. We will do this by extracting the domains from the URLs, and then manually coding these domains as indicating that the organisation is from the Global North or South.
#we use the function defined above, for extracting the domain from a URL
dd <- sapply(df$page, domain)
df$domain <- as.character(dd)
#now create a csv file containing the unique domains
write.csv(unique(df$domain), "domains.csv")
#we code up the domains according to whether the organisations are from global north or south
#then read the coded csv file back into R
coded <- read.csv("domains_coded.csv")
#> head(coded)
# X x type
#1 1 womeninlocalization.com north
#2 2 iwgia.org north
#3 3 indigenousdatalab.org north
#4 4 botpopuli.net south
#5 5 cipesa.org south
#6 6 mydata.org north
#now get the north/south classification into the dataframe containing the tokens
df$type <- coded$type[match(df$domain, coded$x)]
#capitalise the labels, for the plot
df$type <- ifelse(df$type=="north", "North", "South")
#finally, we will create the comparison cloud
library(reshape2)
library(RColorBrewer)
dark2 <- brewer.pal(8, "Dark2")
png("comparison_cloud.png", width=800, height=800)
df %>%
anti_join(stop_words2) %>%
group_by(type) %>%
count(word) %>%
acast(word ~ type, value.var = "n", fill = 0) %>%
comparison.cloud(color = dark2, title.size = 3, scale = c(5, 1), random.order = FALSE, max.words = 200)
dev.off.crop("comparison_cloud.png")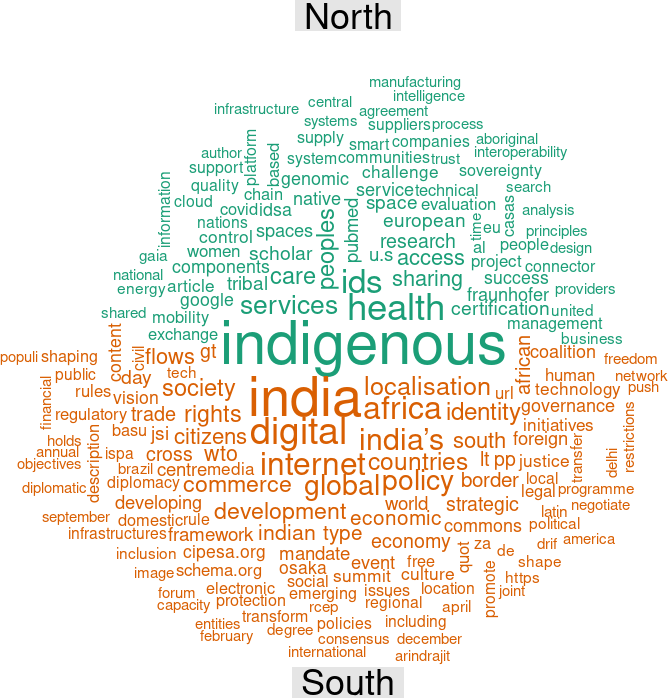
The comparison cloud gives us insights into the differences in keywords used by organisations in Global North and South when discussing the topic ‘data sovereignty’ on the web. It is assumed that North/South divide will be reflected in differences of issue of concern among organisations in both regions proxied by the use of vocabularies or words in their narratives. The graph shows that the terms such as ‘indigenous’, ‘health’, and ‘ids’ are more prominent in the North compared to their South counterpart. Whereas popular terms in the South mention the names of country or region such as ‘India’ and ‘Africa’, along with other terms include ‘digital, ’internet’, and ‘policy’. Our interpretation is that organisations in the North discuss ‘data sovereignty’ in relation to issues about indigenousity, health, and ids or identities. In the Global South, it might be the case that organisations involved in ‘data sovereignty’ debates are simply coming from India and Africa so that they mention these words most frequently, or they are mainly concerned with data issues in India or Africa. Furthermore, other keywords such as ‘digital’, ‘internet’, ‘policy’ appear frequently, and this suggests that the ‘data sovereignty’ topic is discussed by Global South organisations along with their concern of digital and internet policy issues in the South.
A limitation of comparison clouds (and word clouds more generally) is that the location of words in the comparison cloud does not reflect semantic connections between the words and for this reason it is sometimes difficult to understand the context and meaning of words appearing in word clouds. In a future blog post we will use other quantitative text analysis techniques in an attempt to gain more insight into the differences between organisations in the Global North and South, in terms of how they are using the web to promote issues or present narratives relating to data sovereignty.