Introduction to vosonSML
VOSON Lab, Australian National University
Robert Ackland, Bryan Gertzel, Francisca Borquez
04 July, 2025
Source:vignettes/Intro-to-vosonSML.Rmd
Intro-to-vosonSML.RmdThe following guide provides an introduction to using vosonSML, which is
available both on GitHub and CRAN. More
resources are available on the VOSON Lab website (vosonSML and training materials).
For a full list of functions, please refer to the reference
page. The companion package to vosonSML is VOSON Dashboard, which
provides an R/Shiny graphical user interface for data collection (via
vosonSML), network and text analysis.
To use vosonSML, you first need to load it into the
session:
There are three steps involved in data collection and network
creation using vosonSML. These are:
-
Authenticate with the platform API, using the function
Authenticate() -
Collect data from the API and store it for later use, using
Collect() -
Create networks from the collected data, using
Create()andGraph()
YouTube
Authenticating with the YouTube API
To collect YouTube data, it is necessary to first create a Google app
with access to the YouTube Data API via the Google APIs
console and generate an associated API key. The following shows the
creation of a YouTube access token by passing a Google developer API key
to the Autnenticate() function:
# create auth object with api key
youtubeAuth <- Authenticate("youtube", apiKey = "xxxxxxxx")The YouTube access token can optionally be saved to disk for use in a later session:
saveRDS(youtubeAuth, file = "youtube_auth")The following loads into the current session a previously-created authentication object:
youtubeAuth <- readRDS("youtube_auth")Collecting Data from YouTube
The YouTube video IDs (the part after “=” in the YouTube URL) are required in order to collect YouTube comment data. These IDs can either be manually provided or automatically extracted from the URLs:
The character vector containing the YouTube video IDs or URLs is
passed as a parameter to the Collect() function (the
following code also shows the YouTube access token being piped to
Collect()). In the following example, we are collecting
comments from a YouTube video titled “Australia bushfires - a national
catastrophe | DW News”, which was uploaded by the German Deutsche Welle
news service on 5th January 2020. The comment data were collected on
10th January 2020: the total number of comments at that time was over
1100, but we are using the maxComments parameter to collect
a maximum of 500 top-level comments (and all the reply comments to these
top-level comments).
videoID <- "https://www.youtube.com/watch?v=pJ_NyEYRkLQ"
youtubeData <- youtubeAuth |>
Collect(videoID, maxComments = 500, writeToFile = TRUE)The Collect() function takes the following arguments
(when used for collecting YouTube data): credential (object
generated from Authenticate() with class name “youtube”
(above we pass this via the pipe), videoIDs (character
vector specifying one or more youtube video IDs),
maxComments (numeric integer specifying how many top-level
comments to collect from each video), writeToFile (whether
to write the returned dataframe to disk as an .rds file;
default is FALSE), and verbose (whether to output
information about the data collection; default is FALSE).
Collect() returns an R dataframe with the following
structure (data have been modified to preserve anonymity):
> str(youtubeData)
Classes ‘dataource’, ‘youtube’ and 'data.frame': 603 obs. of 12 variables:
$ Comment : chr "xxxxx"
$ AuthorDisplayName : chr "xx" "xx" "xx" "xx"
$ AuthorProfileImageUrl: chr "https://xx" "https://xx" "https://xx"
$ AuthorChannelUrl : chr "http://xx" "http://xx" "http://xx" "http://xx"
$ AuthorChannelID : chr "xx" "xx" "xx" "xx"
$ ReplyCount : chr "0" "0" "0" "0"
$ LikeCount : chr "0" "0" "0" "0"
$ PublishedAt : chr "2020-01-10T02:23:43" "2020-01-09T20:56:23"
"2020-01-09T20:44:00" "2020-01-09T19:31:32"
$ UpdatedAt : chr "2020-01-10T02:23:43" "2020-01-09T20:56:23"
"2020-01-09T20:44:00" "2020-01-09T19:31:32"
$ CommentID : chr "xx" "xx" "xx" "xx"
$ ParentID : chr NA NA NA NA
$ VideoID : chr "pJ_NyLQ" "pJ_NyLQ" "pJ_NyLQ" "pJ_NyLQ"Importing saved collection data from file
If you are reading a previously saved writeToFile
YouTube dataframe from disk, you simply need to use the
readRDS function:
# read dataframe from file
youtubeData <- readRDS("2020-09-26_095354-YoutubeData.rds")Creating YouTube Networks
It is currently possible to create two types of networks using YouTube data: (1) actor network and (2) activity network.
Actor Network
In the YouTube actor network the nodes are users who have commented on videos (and the videos themselves are included in the network as special nodes) and the edges are the interactions between users in the comments. We can distinguish a top-level comment, which is a comment that is directed to a video from a reply comment, which is a comment directed to a top-level comment. The YouTube user interface does not allow a user to direct a reply to another reply. However, users can achieve the “reply to a reply” functionality by starting their comment with the username of the person that they are replying to (and they often prepend the username with “@”). So there will be an edge from user i to user j if i replied to a top-level comment authored by j or else i prepended their comment with j’s username.
actorNetwork <- youtubeData |> Create("actor") |> AddText(youtubeData)
actorGraph <- actorNetwork |> Graph(writeToFile = TRUE)Create("actor") returns a named list containing two
dataframes named “nodes” and “edges” (the following has been modified to
preserve anonymity):
> actorNetwork
$nodes
# A tibble: 522 x 3
id screen_name node_type
<chr> <chr> <chr>
1 xxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxx actor
2 xxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx actor
[snip]
# … with 512 more rows
$edges
# A tibble: 604 x 6
from to video_id comment_id edge_type vosonTxt_comment
<chr> <chr> <chr> <chr> <chr> <chr>
1 xxxxxxxx… VIDEOID… pJ_NyEY… xxxxxxxxxxx… comment "xxxxx"
2 xxxxxxxx… VIDEOID… pJ_NyEY… xxxxxxxxxxx… comment "xxxxx"
[snip]
# … with 594 more rows
attr(,"class")
[1] "list" "network" "actor" "youtube" "voson_text"Note that in the above, AddText() was used to add the
comment text data to the network dataframe, stored as an edge attribute.
Also, note that there is an optional parameter
replies_from_text that can be passed to
AddText() when used with YouTube network creation, to
extract the “reply to reply” comments.
This list is then passed to Graph(), which returns an
igraph graph object. Remember that it is possible to
achieve the above using a single line of code:
The following is an an annonymised summary of the igraph
graph object.
> actorGraph
IGRAPH 79e5456 DN-- 522 604 --
+ attr: type (g/c), name (v/c), screen_name (v/c), node_type (v/c),
| label (v/c), video_id (e/c), comment_id (e/c), edge_type (e/c),
| vosonTxt_comment (e/c)
+ edges from 79e5456 (vertex names):
[1] xxxx->VIDEOID:pJ_NyEYRkLQ
[2] xxxx->VIDEOID:pJ_NyEYRkLQ
[snip]
+ ... omitted several edgesThe YouTube actor network node contains a graph attribute
type (set to “youtube”). The node attributes are:
name (Channel ID, which is YouTube’s unique user ID),
screen_name (the users displayed name),
node_type (‘actor’ or ‘video’) and label (a
concatenation of the ID and screen name). The edge attributes are:
video_id (the ID of the video for which the data have been
collected), comment_id (the ID of the comment),
edge_type (whether the edge is a ‘comment’ i.e. top-level
comment, ‘reply-comment’ i.e. reply to top-level comment or reply to
reply or ‘self-loop’, which is a special edge connecting the video to
itself, as a means of including text posted with the video). In the
above example, because of our earlier use of AddText(),
there is also an edge attribute vosonTxt_comment which is
the text associated with the comment, reply or video.
The example YouTube actor network contains 522 nodes and 604 edges.
The following indicates that there were 500 top-level comments (we
constrained the collection to this number), 103 replies to top-level
comments (note: we did not use AddText() to collect replies
embedded within the text), and there is the single self-loop from the
video to itself.
We can visualize this network, using red to identify the video nodes.
# change color of nodes with type video to red and others grey
V(actorGraph)$color <- ifelse(
V(actorGraph)$node_type == "video", "red", "grey"
)
# open and write plot to a png file
png("youtube_actor.png", width = 600, height = 600)
plot(actorGraph, vertex.label = "", vertex.size = 4, edge.arrow.size = 0.5)
dev.off()
The following creates a sub-network containing only the replies to top-level comments. In removing the other edges (top-level comments and the self-loop) we create a number isolate nodes (nodes with no connections) that we also remove. We have also used red to indicate the people who have written comments containing particular terms that have been present in the online commentary about the bushfires.
# removed edges that are not of type reply-comment
g2 <- delete.edges(
actorGraph, which(E(actorGraph)$edge_type != "reply-comment")
)
# check number of isolates
> length(which(degree(g2) == 0))
[1] 417
# remove isolates
g2 <- delete.vertices(g2, which(degree(g2) == 0))
# get node indexes for the tails of edges that have comments containing
# words of interest change the indexed node colors to red and others grey
V(g2)$color <- "grey"
ind <- tail_of(
actorGraph,
grep("arson|backburn|climate change", tolower(E(g2)$vosonTxt_comment))
)
V(g2)$color[ind] <- "red"
# open and write plot to a png file
png("youtube_actor_reply.png", width = 600, height = 600)
plot(g2, vertex.label = "", vertex.size = 4, edge.arrow.size = 0.5)
dev.off()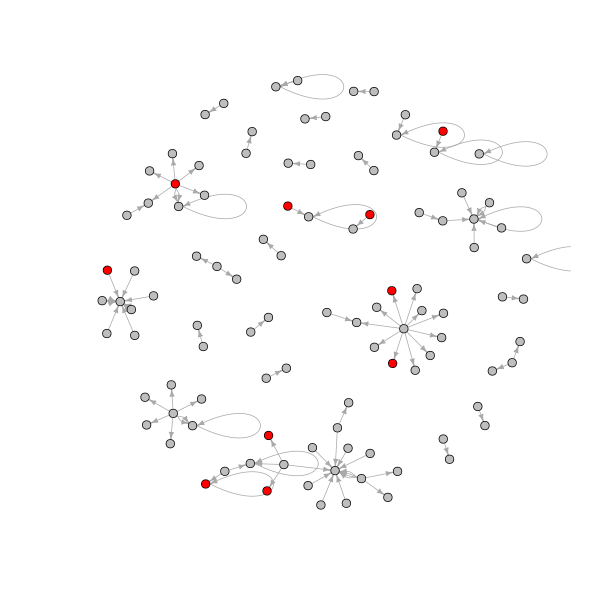
Finally, the AddVideoData() function supplements the
network data with additional video information.
actorNetwork_withVideoInfo <- actorNetwork |> AddVideoData(youtubeAuth)AddVideoData() returns a named list containing three
dataframes named “nodes” (identical to the dataframe contained in the
list actorNetwork in the example able), “edges” (this has
three additional columns: “video_title”, “video_description”,
“video_published_at”) and a new dataframe “videos” (the following has
been modified to preserve anonymity):
> actorNetwork_withVideoInfo
$nodes
# A tibble: 522 x 3
id screen_name node_type
<chr> <chr> <chr>
1 xxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx actor
2 xxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx actor
[snip]
# … with 512 more rows
$edges
# A tibble: 604 x 9
from to video_id comment_id edge_type vosonTxt_comment video_title
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 xxxx… xxxx… pJ_NyEY… xxxxxxxxx… comment xxxxxxxxxxxx … Australia …
2 xxxx… xxxx… pJ_NyEY… xxxxxxxxx… comment "xxxx" Australia …
[snip]
# … with 594 more rows, and 2 more variables: video_description <chr>,
# video_published_at <chr>
$videos
# A tibble: 1 x 6
VideoID VideoTitle VideoDescription VideoPublishedAt ChannelID ChannelTitle
<chr> <chr> <chr> <chr> <chr> <chr>
1 pJ_NyEY… Australia … "As Australia ba… 2020-01-05T12:3… UCknLrEd… DW News
attr(,"class")
[1] "list" "network" "actor" "youtube"
[5] "voson_text" "voson_video_data"It should also be noted that AddVideoData() can
optionally substitute references to the video ID in the “nodes” and
“edges” dataframes with the video publishers channel ID (this is done by
setting the parameter actorSubOnly to TRUE.
Activity Network
In the YouTube activity network, nodes are either comments or videos (videos represent a starting comment).
activityNetwork <- youtubeData |> Create("activity") |> AddText(youtubeData)
activityGraph <- activityNetwork |> Graph()Create("activity") returns a named list containing two
dataframes named “nodes” and “edges” (the following has been modified to
preserve anonymity).
> activityNetwork
$edges
# A tibble: 603 x 3
from to edge_type
<chr> <chr> <chr>
1 xxxxxxxxxxxxxxxxxxxxxxxxxx VIDEOID:pJ_NyEYRkLQ comment
2 xxxxxxxxxxxxxxxxxxxxxxxxxx VIDEOID:pJ_NyEYRkLQ comment
[snip]
# … with 593 more rows
$nodes
# A tibble: 604 x 8
id video_id published_at updated_at author_id screen_name node_type
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 xxxx… pJ_NyEY… 2020-01-10T… 2020-01-1… xxxxxxxx… xxxxxxxxxx… comment
2 xxxx… pJ_NyEY… 2020-01-09T… 2020-01-0… xxxxxxxx… xxxxxxxxxx… comment
[snip]
# … with 594 more rows, and 1 more variable: vosonTxt_comment <chr>
attr(,"class")
[1] "list" "network" "activity" "youtube" "voson_text"Note that in the above, AddText() was used to add the
comment text data to the network dataframe, stored as a node attribute.
This list is then passed to Graph(), which returns an
igraph graph object (this has been anonymised).
IGRAPH 02664d1 DN-- 604 603 --
+ attr: type (g/c), name (v/c), video_id (v/c), published_at (v/c),
| updated_at (v/c), author_id (v/c), screen_name (v/c), node_type
| (v/c), vosonTxt_comment (v/c), label (v/c), edge_type (e/c)
+ edges from 02664d1 (vertex names):
[1] xxxx->VIDEOID:pJ_NyEYRkLQ
[2] xxxx->VIDEOID:pJ_NyEYRkLQ
[3] xxxx->VIDEOID:pJ_NyEYRkLQ
[4] xxxx->VIDEOID:pJ_NyEYRkLQ
[5] xxxx->VIDEOID:pJ_NyEYRkLQ
[6] xxxx->VIDEOID:pJ_NyEYRkLQ
+ ... omitted several edgesThe YouTube activity network contains a graph attribute
type (set to “youtube”). The node attributes are:
name (character string ID number for the comment or video),
video_id (character string ID of the video for which the
comments collected - in this example, “pJ_NyEYRkLQ”),
published_at (timestamp of when the comment was published,
this is NA for the video itself), updated_at
(timestamp of when a comment was updated), author_id
(user’s Channel ID), screen_name (user’s display name),
node_type (whether the node is a ‘comment’ i.e. top-level
comment, ‘reply-comment’ i.e. reply to top-level comment or reply to
reply or ‘video’), vosonText_comment (the comment text,
NA for the video), label (concatenation of
name and screen_name). The edge attributes
edge_type which is ‘comment’ for all edges connecting a
top-level comment to the video, and ‘reply-comment’ for all other
edges.
The example YouTube activity network contains 604 nodes and 603
edges. The following is an igraph visualization of the
network, where the video is indicated by a red node, and blue indicates
comments that include one of the following terms: “arson”, “bakcburn”,
“climate change”.
# set all video node colors to red and others to grey
V(activityGraph)$color <- "grey"
V(activityGraph)$color[which(V(activityGraph)$node_type == "video")] <- "red"
# get node indexes of comments that contain terms of interest
# set their node colors to blue
ind <- grep(
"arson|backburn|climate change", tolower(V(activityGraph)$vosonTxt_comment)
)
V(activityGraph)$color[ind] <- "blue"
# open and write plot to a png file
png("youtube_activity.png", width = 600, height = 600)
plot(activityGraph, vertex.label = "", vertex.size = 4, edge.arrow.size = 0.5)
dev.off()
The Reddit collection in vosonSML is based on the
approach used in the RedditExtractoR
package.
Authenticating with the Reddit API
The vosonSML does not require Reddit API credentials to
be provided. However, to keep the workflow consistent with the other
data sources, we still need to create a “dummy” access token, using the
Authenticate() function (see below).
Collecting Data from Reddit
To collect Reddit comment data, first construct a character vector containing the post URL(s).
myThreadUrls <- c(
"https://www.reddit.com/r/xxxxxx/comments/xxxxxx/x_xxxx_xxxxxxxxx/",
"https://www.reddit.com/r/xxxxxx/comments/xxxxxx/x_xxxx_xxxxxxxxx/"
)This character vector is then passed as an argument to the
Collect() function. In the example below, a post relating
to the politics around the Australian bushfires was used: https://www.reddit.com/r/worldnews/comments/elcb9b/australias_leaders_deny_link_between_climate/.
This post was created on 7th January 2020 and by the time of data
collection (10th January), it had attracted over 4000 comments. The
maximum number of comments available for retrieval is 500 per thread or
post.
Reddit has implemented a feature in their latest site re-design to
branch off into new threads, when a thread reaches a breadth (diameter)
of 10 comments. These appear as ‘Continue this thread’ links in thread
discussions on the reddit site, and as new listing markers within the
collected thread data. vosonSML follows these links with
additional thread requests and collects comments from those as well,
capturing a more complete data set, as the limit of 500 comments applies
to each ‘new’ thread.
myThreadUrls <- "https://www.reddit.com/r/worldnews/comments/elcb9b/australias_leaders_deny_link_between_climate/"
redditData <- Authenticate("reddit") |>
Collect(threadUrls = myThreadUrls, writeToFile = TRUE)The Collect() function takes the following arguments
(when used for collecting Reddit data): credential (an
object generated from Authenticate() with class name
“reddit” (above we pass this via the pipe), threadUrls
(character vector of Reddit thread urls), waitTime (a
numeric vector giving the time range in seconds to select random wait
url collection requests; default is c(3, 10) i.e. random
wait between 3 and 10 seconds), ua (User-Agent string;
default is option("HTTPUserAgent") as set by vosonSML,
writeToFile (whether to write the returned dataframe to
file as an .rds file; default is FALSE),
verbose (whether to output information about the data
collection; default is TRUE).
The Collect() function returns a tibble
dataframe (this output has been anonymised):
> str(redditData)
Classes ‘tbl_df’, ‘tbl’, ‘datasource’, ‘reddit’ and 'data.frame':
767 obs. of 22 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ structure : chr "1" "4_1_1_1_1_1_1_1_1_1" "4_1_1_4_2_1_1_1_1_1" ...
$ post_date : chr "2020-01-07 14:34:58" "2020-01-07 14:34:58" ...
$ post_date_unix : num 1.58e+09 1.58e+09 1.58e+09 1.58e+09 1.58e+09 ...
$ comm_id : chr "xxxx" "xxxx" "xxxx" "xxxx" ...
$ comm_date : chr "2020-01-07 19:11:10" "2020-01-07 21:04:05" ...
$ comm_date_unix : num 1.58e+09 1.58e+09 1.58e+09 1.58e+09 1.58e+09 ...
$ num_comments : int 4435 4435 4435 4435 4435 4435 4435 4435 4435 4435 ...
$ subreddit : chr "worldnews" "worldnews" "worldnews" "worldnews" ...
$ upvote_prop : num 0.91 0.91 0.91 0.91 0.91 0.91 0.91 0.91 0.91 0.91 ...
$ post_score : int 45714 45714 45714 45712 45714 45710 45720 45712 ..
$ author : chr "xxxx" "xxxx" "xxxx" "xxxx" ...
$ user : chr "xxxx" "xxxx" "xxxx" "xxxx" ...
$ comment_score : int 1904 136 17 13 9 9 125 4 6 12 ...
$ controversiality: int 0 0 0 0 0 0 0 0 0 0 ...
$ comment : chr "xxxx...
$ title : chr "Australia’s leaders deny link between climate change and the country’s devastating bushfires" "Australia’s leaders deny link between climate change and the country’s devastating bushfires" "Australia’s leaders deny link between climate change and the country’s devastating bushfires" "Australia’s leaders deny link between climate change and the country’s devastating bushfires" ...
$ post_text : chr "" "" "" "" ...
$ link : chr "https://www.theglobeandmail.com/world/article-australias-leaders-unmoved-on-climate-action-after-devastating-2/" "https://www.theglobeandmail.com/world/article-australias-leaders-unmoved-on-climate-action-after-devastating-2/" "https://www.theglobeandmail.com/world/article-australias-leaders-unmoved-on-climate-action-after-devastating-2/" "https://www.theglobeandmail.com/world/article-australias-leaders-unmoved-on-climate-action-after-devastating-2/" ...
$ domain : chr "theglobeandmail.com" "theglobeandmail.com" "theglobeandmail.com" "theglobeandmail.com" ...
$ url : chr "https://www.reddit.com/r/worldnews/comments/elcb9b/australias_leaders_deny_link_between_climate/" "https://www.reddit.com/r/worldnews/comments/elcb9b/australias_leaders_deny_link_between_climate/" "https://www.reddit.com/r/worldnews/comments/elcb9b/australias_leaders_deny_link_between_climate/" "https://www.reddit.com/r/worldnews/comments/elcb9b/australias_leaders_deny_link_between_climate/" ...
$ thread_id : chr "elcb9b" "elcb9b" "elcb9b" "elcb9b" ...Importing saved collection data from file
If you are reading a previously saved writeToFile Reddit
dataframe from disk, you simply need to use the readRDS
function.
redditData <- readRDS("2020-09-26_095354-RedditData.rds")Creating Reddit Networks
It is currently possible to create two types of networks using Reddit data: (1) actor network and (2) activity network.
Actor Network
In the Reddit actor network, nodes represent users who have posted original posts and comments and the edges are the interactions between users in the comments i.e. where there is an edge from user i to user j if i writes a comment that replies to user j’s comment (or the original post).
The following creates a Reddit actor network with comment text as an edge attribute (as above, this can be achieved in a single line of code, but we split it into two lines to better explain the objects that are created).
actorNetwork <- redditData |> Create("actor") |> AddText(redditData)
actorGraph <- actorNetwork |> Graph(writeToFile = TRUE)Create("actor") returns a named list containing two
dataframes named “nodes” and “edges” (the following has been modified to
preserve anonymity):
> actorNetwork
$nodes
# A tibble: 439 x 2
id user
<int> <chr>
1 1 xxxxxxxxxx
2 2 xxxxxxxxxxxxxx
[snip]
# … with 429 more rows
$edges
# A tibble: 768 x 8
from to subreddit thread_id comment_id comm_id vosonTxt_comment title
<int> <int> <chr> <chr> <dbl> <chr> <chr> <chr>
1 1 439 worldnews elcb9b 1 xxxxxxx "xxxxxxxxxxxxxxxxxxx NA
2 2 73 worldnews elcb9b 2 xxxxxxx "xxxxxxxxxxxxxxxxxxx NA
[snip]
… with 758 more rows
attr(,"class")
[1] "list" "network" "actor" "reddit" "voson_text"Note that in the above, AddText() was used to add the
comment text data to the network dataframe, stored as an edge attribute.
This list is then passed to Graph(), which returns an
igraph graph object.
> actorGraph
IGRAPH 5a5d5b9 DN-- 439 768 --
+ attr: type (g/c), name (v/c), user (v/c), label (v/c), subreddit
| (e/c), thread_id (e/c), comment_id (e/n), comm_id (e/c),
| vosonTxt_comment (e/c), title (e/c)
+ edges from 5a5d5b9 (vertex names):
[1] 1 ->439 2 ->73 3 ->113 4 ->120 5 ->120 6 ->17 7 ->194 8 ->20 9 ->20
[10] 10->165 11->165 12->1 13->2 14->3 15->4 16->5 17->6 18->7
[19] 19->8 20->9 21->10 22->11 23->12 2 ->13 24->3 7 ->18 25->23
[28] 26->2 3 ->24 27->18 28->1 29->2 18->27 1 ->28 30->2 31->7
[37] 25->1 32->2 33->31 34->1 2 ->32 35->7 25->34 36->2 7 ->35
[46] 37->1 38->2 39->7 40->1 41->2 42->7 43->1 2 ->41 44->7
+ ... omitted several edgesThe Reddit actor network contains a graph attribute type
(set to “reddit”). The node attributes are: name
(sequential ID number for actor, generated by vosonSML),
user (Reddit handle or screen name)) and label
(a concatenation of the ID and screen name). The edge attributes are:
subreddit (the subreddit from which the post is collected),
thread_id (the 6 character ID of the thread or post),
comment_id (sequential ID number for comment, generated by
vosonSML). There is also an edge attribute
title, which is set to NA for all comments
except the comment representing the original post. Further note that the
original post is represented as a self-loop edge from the user who
authored the post (and this is how the post text can be accessed, as an
edge attribute), however with the Reddit actor network, there is no
edge_type attribute. Finally, because we used
AddText() in the above example, there is also an edge
attribute vosonTxt_comment which is the text associated
with the comment, or original post.
The example Reddit actor network contains 439 nodes and 768 edges. The following is a visualization of the actor network, where the author of the post is indicated by a red node, and blue nodes indicate those people who mentioned “arson” or “starting fires” in at least one of their comments.
# set node color of original post to red based on presence of title edge
# attribute set other node colors to grey
V(actorGraph)$color <- "grey"
V(actorGraph)$color[tail_of(
actorGraph, which(!is.na(E(actorGraph)$title))
)] <- "red"
# get node indexes for the tails of edges that have comments containing
# words of interest set their node colors to blue
ind <- tail_of(
actorGraph,
grep("arson|starting fires",
tolower(E(actorGraph)$vosonTxt_comment))
)
V(actorGraph)$color[ind] <- "blue"
# open and write plot to a png file
png("reddit_actor.png", width = 600, height = 600)
plot(actorGraph, vertex.label = "", vertex.size = 4, edge.arrow.size = 0.5)
dev.off()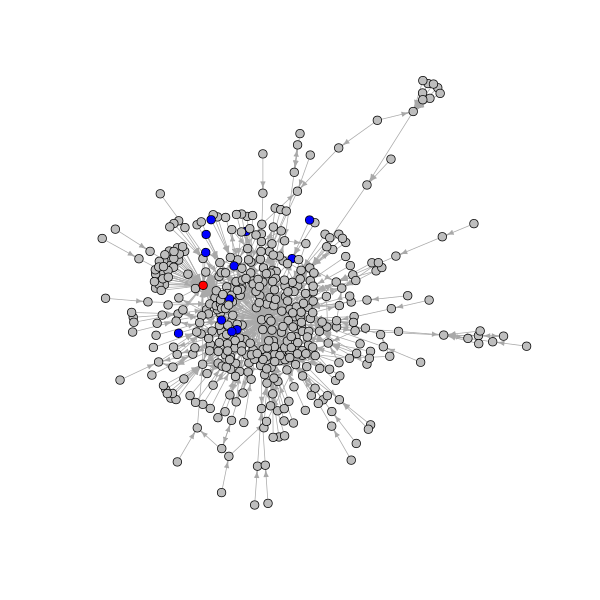
Activity Network
In the Reddit activity network, nodes are either comments and/or initial thread posts and the edges represent replies to the original post, or replies to comments.
activityNetwork <- redditData |> Create("activity") |> AddText(redditData)
activityGraph <- activityNetwork |> Graph(writeToFile = TRUE)Create("activity") returns a named list containing two
dataframes named “nodes” and “edges” (the following has been modified to
preserve anonymity):
> activityNetwork
$nodes
# A tibble: 768 x 10
id thread_id comm_id datetime ts subreddit user node_type
<chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
1 elcb… elcb9b xxxxxxx 2020-01… 1.58e9 worldnews xxxx… comment
2 elcb… elcb9b xxxxxxx 2020-01… 1.58e9 worldnews xxxx… comment
[snip]
# … with 758 more rows, and 2 more variables: vosonTxt_comment <chr>,
# title <chr>
$edges
# A tibble: 767 x 3
from to edge_type
<chr> <chr> <chr>
1 elcb9b.1 elcb9b.0 comment
2 elcb9b.4_1_1_1_1_1_1_1_1_1 elcb9b.4_1_1_1_1_1_1_1_1 comment
[snip]
# … with 757 more rows
attr(,"class")
[1] "list" "network" "activity" "reddit" "voson_text"Note that in the above, AddText() was used to add the
comment text data to the network dataframe, stored as a node attribute.
This list is then passed to Graph(), which returns an
igraph graph object.
> activityGraph
IGRAPH 09e30ea DN-- 768 767 --
+ attr: type (g/c), name (v/c), thread_id (v/c), comm_id (v/c),
| datetime (v/c), ts (v/n), subreddit (v/c), user (v/c), node_type
| (v/c), vosonTxt_comment (v/c), title (v/c), label (v/c), edge_type
| (e/c)
+ edges from 09e30ea (vertex names):
[1] elcb9b.1 ->elcb9b.0
[2] elcb9b.4_1_1_1_1_1_1_1_1_1->elcb9b.4_1_1_1_1_1_1_1_1
[3] elcb9b.4_1_1_4_2_1_1_1_1_1->elcb9b.4_1_1_4_2_1_1_1_1
[4] elcb9b.4_1_1_4_3_1_1_1_3_1->elcb9b.4_1_1_4_3_1_1_1_3
[5] elcb9b.4_1_1_4_3_1_1_1_3_2->elcb9b.4_1_1_4_3_1_1_1_3
+ ... omitted several edgesThe Reddit activity network contains a graph attribute
type (set to “reddit”). The node attributes are:
name (string showing position of the comment in the
thread), date (date when the comment was authored, in
DD-MM-YY format), subreddit (the subreddit from which the
post is collected), user (Reddit handle or screen name of
the user who authored the comment or post), node_type
(‘comment’ or ‘thread’), title (NA for all
nodes except that representing the original post), label (a
concatenation of name and user). Because we
used AddText() in the above example, there is also a node
attribute vosonTxt_comment which is the text from the
comment, or original post. The edge attributes is edge_type
which is ‘comment’ for all edges.
The example Reddit activity network contains 768 nodes and 767 edges. The following is a visualisation of the network, where the post is indicated by a red node, and blue indicates those comments that include the words “arson” or “starting fires”.
# set original post node colors to red based on a node type of thread
# set other node colors to grey
V(activityGraph)$color <- "grey"
V(activityGraph)$color[which(V(activityGraph)$node_type == "thread")] <- "red"
# get node indexes for nodes that have comment attributes containing words of interest
# set their node colors to blue
ind <- grep("arson|starting fires", tolower(V(activityGraph)$vosonTxt_comment))
V(activityGraph)$color[ind] <- "blue"
# open and write plot to a png file
png("reddit_activity.png", width = 600, height = 600)
plot(activityGraph, vertex.label = "", vertex.size = 4, edge.arrow.size = 0.5)
dev.off()
Merging Collected Data
Data that was collected at different times, used different collect
parameters or was saved to multiple files can be merged by using
functions that operate on dataframes. The data from Collect
is output in tibble (dataframe) format and provided each
collected data set are from the same social media type can be combined
using the rbind function.
In the examples below or cases that involve large datasets, it can
sometimes be more efficient or timely to substitute optimized functions
such as dplyr::bind_rows for rbind or
data.table::rbindlist instead of
do.call("rbind", list).
Merging from multiple Collect operations
Data collected in the same session can be merged using the
Merge function.
VOSON Dashboard
It is possible to import a network created using
vosonSML, and saved as a “.graphml” file, into
VOSON Dashboard. However, if you have created a categorical
node attribute in the network and wish to plot networks in
VOSON Dashboard with node colour reflecting the node
attribute, then the node attribute name has to be pre-pended with
“vosonCA_”. This let’s VOSON Dashboard know the attribute
is to be treated as categorical.
The following network is a Twitter subnetwork, specifically the giant
component in a reply network, with red nodes indicating those users who
tweeted using the word “bushfire”. It was accomplished by creating a
node attribute “tweetedBushfires”. For VOSON Dashboard to
recognise this node attribute, it has to be named
“vosonCA_tweetedBushfires”. The following code creates a new node
attribute with this name, and sames the network as a graphml file:
V(g3)$vosonCA_tweetedBushfires <- V(g3)$tweetedBushfires
write.graph(g3, "g3.graphml", format = "graphml")The following shows a screenshot of VOSON Dashboard with
this network loaded and the “tweetedBushfires” attribute has been
seleced to be reflected in the node colour.
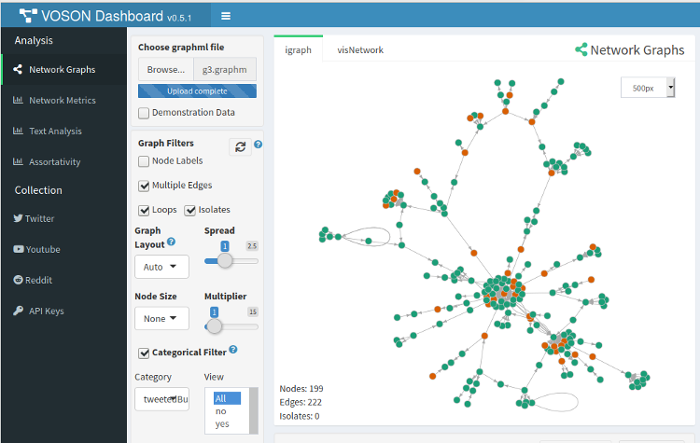
Acknowledgements
vosonSML and VOSON Dashboard are developed
and maintained at the Virtual Observatory
for the Study of Online Networks (VOSON) Lab at the Australian
National University.
vosonSML was originally released on CRAN in November
2015 as the package SocialMediaLab (Timothy Graham was the
lead developer), with the significantly revised and renamed
vosonSML being released on CRAN in July 2018 (Bryan Gertzel
is the lead developer).
We acknowledge the contributions of Chung-hong Chan who implemented a
revised UI (involving magrittr pipes) in the original
SocialMediaLab package and Xiaolan Cai who has contributed
to documentation.